Large Language Model (LLM) Usage Dashboard
As a SUVA admin, it is equally relevant for you to know the costs incurred by the LLM-powered chatbot. When your SUVA chatbot is integrated with an LLM like OpenAI, Claude, etc, each API request to LLM has input and output/generated tokens.
Through the Usage Dashboard, you can view the LLM's token consumption within a month. Given below is how the Usage Dashboard looks like:
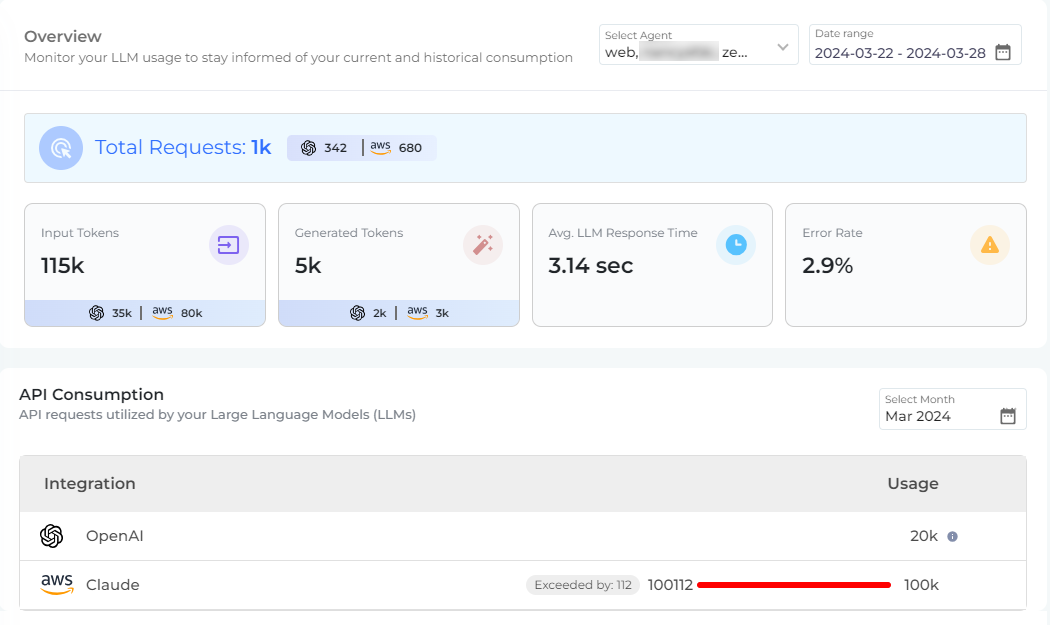
To start with the dashboard analytics, select a Virtual Agent and the Date Range for which you want to see the consumption data. The first section of the Usage Dashboard, Overview, shows the following details:
-
Total Requests. The total number of API requests consumed by the large language model. An API request comprises of few input and generated tokens.
When you expand the Total Requests section, you can see the details of the LLM requests. The details include; A) Requester Email, B) Agent Name, C) LLM, D) Requested Time, and E) Request Type.
Some examples of Request Type are Case Summary generation, Synthetic Utterance generation, and General response, etc.

-
Input Tokens. The total number of tokens sent to the LLM in form of the user input or to say the utterance and for other requests.
-
Generated Tokens. The total number of tokens consumed to generate desired output of the requests.
-
Average LLM Request Time. The average time taken by the large language model to generate chatbot responses.
-
Error Rate. The rate of errors; meaning when the LLM failed to generate a response or it failed due to some technical error.
In the second part of the dashboard, API Consumption, you can see the monthly consumption of API requests of large language model(s). You can see how the API consumption fared against the allotted monthly quota. Admins also get notification via email when the 50 percent, 90 percent, and 100 percent of the allotted quota is consumed.
However, if the monthly API consumption limit has been reached, that won't impact your chatbot operations. The chatbot will continue to work without any interruptions, but Admins would be able to see the number of API requests exceeded beyond the allotted limit. An example of that is as shown below:

Last updated: Friday, July 17, 2026